
今までもデータベースは触っていたのですが、データベースの設計についてはあまり知らなかったため、

を読んで実際にデータベースを設計してみました。データベース設計は概念データモデリング、論理データモデリング、物理データモデリングの3つの工程からなります。この3つを順にやっていくことにします。題材として「本好きのためのSNS」というアプリのためのデータベースをつくることにしてみます。
概念データモデリング
概念データモデリングとは
システム化の準備として、対象範囲にある業務プロセスと関連するデータ項目をすべて洗い出し、業務とデータ項目の関係をデータの集合体のレベルでモデル化すること
です。要するにシステムの対象となるデータとプロセスを明確にすることです。今回の例では次のようにしておきます。
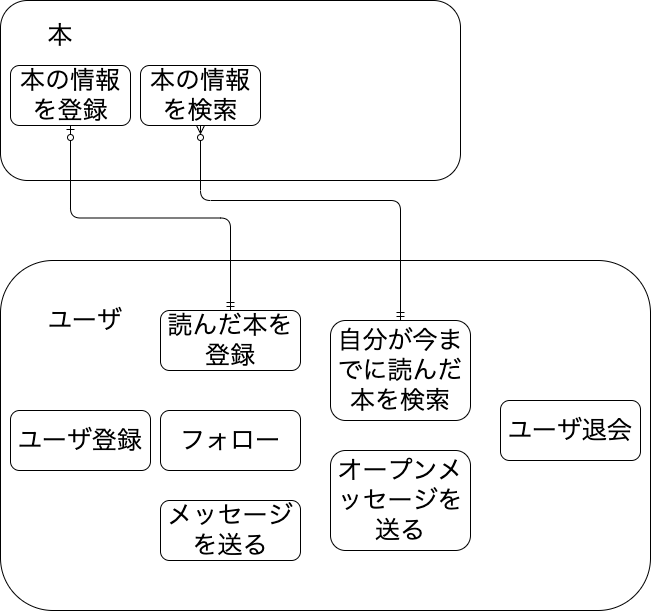
ER図のリレーションっぽく書いていますが、そこまで厳密な意味をもっては書いてないです。
論理データモデリング
論理データモデリングの目的は2つあり
信頼性の高いデータを格納する将来にわたって一元的にデータを管理できること
です。一つ目の「信頼性の高いデータ」とはデータの不整合が発生しにくいデータの持ち方のことです。例えばある本の名前をbooksという本のデータを持つテーブルとreadというユーザがどの本を読んだか管理するテーブルの両方で管理していたとします。このとき本の名前を変えようと思ったときに
2箇所のデータを間違いなく変更しなければなりません。もしミスがあれば不整合が発生することになります。このような重複をなくすようにデータを持ちます。このような作業は「正規化」と呼ばれることがあります。
2つ目はルールの変更などに強い安定したデータ構造を作るということです。たとえば本のジャンルが一つの本につき一種類しか登録できないとします。しかしある都合で、一つの本に複数のジャンルを登録したくなりました。このようなルールの変更が起こってもできるだけデータベースの変更をせずに済むような構造にするということです。
正規化
とりあえず概念データモデリングが終わって次のような感じでデータを持とうと考えていました。
- ユーザ
| ユーザ(R) | ||
| PK | user_ID | 整数 |
| username | 文字列 | |
| password | 文字列 |
| フレンド(R) | ||
| PK,FK | follower | 整数 |
| PK,FK | followee | 整数 |
- メッセージ
| メッセージ(E) | ||
| PK | message_id | 整数 |
| FK | sender_id | 整数 |
| FK | receiver_id | 整数 |
| content | 文字列 | |
| send_at | 時刻 |
- オープンメッセージ
| オープンメッセージ(E) | ||
| PK | open_message_id | 整数 |
| FK | sender_id | 整数 |
| content | 文字列 | |
| send_at | 時刻 |
- 本
| 本(R) | ||
| PK | book_id | 整数 |
| FK | author_id | 整数 |
| FK | genre_id | 整数 |
| ユーザ本(E) | ||
| PK,FK | user_id | 整数 |
| PK,FK | book_id | 整数 |
| thoughts(感想) | 文字列 | |
| read_at | 日付 |
| 筆者(R) | ||
| PK | author_id | 整数 |
| name | 文字列 |
| ジャンル(R) | ||
| PK | genre_id | 整数 |
| name | 文字列 |
ここから正規化を施していきます。プライマリーキーが一意となるようにするのが第一正規化です。これはプラマリーキーを考えながらつくると達成されてしまっていました。
つぎに複合キーに関する重複を排除します。複合キーのうちなかのあるキーを決めるとそれ以外のキーで一意に決まってしまうアトリビュートがある場合はそれを別のエンティティに分離します。これを第二正規化と言います。これもこのなかにはありません。
最後に非キー同士の重複を排除します。つまりある非キーがきまるとそれから一意に決まってしまうアトリビュートがある場合はそれを別のエンティティに分離します。これを第三正規化と言います。これもこの中にはありません。
software designの記事を一回全部読んでから実際にデータベースを設計したらどうなるんだろうとおもってやってみましたが、読んだ知識にすでに影響を受けて正規化してしまっているような気がします。
何はともあれ、正規化してから作成したER図が以下です。
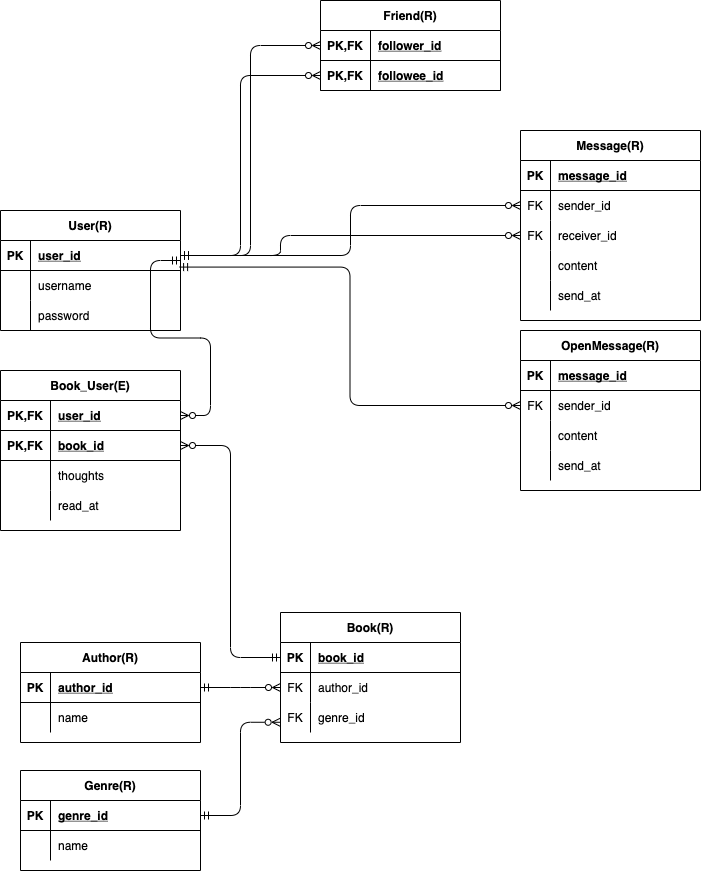
(図はdraw.ioで作成しました。以降の図も同様です)
つぎに最適化を行うのですが、扱うエンティティの数がそれほど多くなく、すべてのエンティティを同時に正規化してしまったので飛ばします。
ビジネスルール検証
システム上のルールに従っているかを確認するのがビジネスルール検証です。ここで一つの本に一種類のジャンルしかつけられるようになっていないことに気づきました。「一つの本に複数のジャンルをつけられるようにする」というルールとこれは矛盾します(このルールは概念データモデリングで決めておくべき)。そのため books_genres のような多対多のテーブルを用意することにしました。
安定性検証
つぎに将来の変化に対して強いデータ構造にするのが安定性検証です。ここではプライマリーキーの安定性検証をしたいと思います。たとえば「ユーザ本」のエンティティを見ると、user_id,book_id で複合キーとしています。これではたとえば同じ本を2回読んだことを登録することはできません。
これにはほかの read_id といったPKを新たに作って user_id,book_id を非キーとすることで対応できます。
これらの作業の後に綺麗に作り直したER図が以下になります。

これをもとに物理データモデリングを進めていきます。
物理データモデリング
物理データモデリングの目的は
データ構造の安定性を保ちながらRDBMSに実装できる「動くデータベース」にすること
です。まず論理データモデリングで作成した図を用いてCRUD図を書きます。これを書くことでプロセスとデータの関係性が目に見えてわかるようになります。
| User | Book | Author | Genre | Read | Follow | Message | OpenMessage | |
| ユーザ登録 | C | |||||||
| ユーザログイン | R | |||||||
| ユーザ画面作成 | R | R | R | R | ||||
| ユーザ消す | D | D | D | D | D | |||
| 読んだ本を登録 | U | C | C | C | C | |||
| 読んだ本の情報を更新 | U | U | U | U | U | |||
| 本を検索 | R | R | R | |||||
| 10年経過 | D | D | D | |||||
| フレンド追加 | C | |||||||
| フレンド削除 | D | |||||||
| メッセージ送信 | C | |||||||
| オープンメッセージ送信 | C |
ユーザ画面作成のところが少しざつですが、上のような感じになります。上の図ですべてのエンティティにC,Dがあることなどを確認します。また、イベントエンティティとリソースエンティティに分けて、プロセスを上からイベントエンティティを左から発生順に並び替えてCが左上から右下に並んでいくことを確認します。
| Read | Follow | Message | OpenMessage | User | Book | Author | Genre | |
| ユーザ登録 | C | |||||||
| ユーザログイン | R | |||||||
| 読んだ本を登録 | C | U | C | C | C | |||
| 読んだ本の情報を更新 | U | U | U | U | U | |||
| 本を検索 | R | R | R | |||||
| フレンド追加 | C | U | ||||||
| フレンド削除 | D | |||||||
| メッセージ送信 | C | U | ||||||
| オープンメッセージ送信 | C | U | ||||||
| ユーザ画面作成 | R | R | R | R | ||||
| 10年経過 | D | D | D | |||||
| ユーザ消す | D | D | D | D | D |
テーブル設計
つぎにテーブルを実際に設計していきます。これにはテーブル名、カラム名、データ型、制約、インデックスをどのようにするか決める作業が含まれます。ここでは必須項目にNOT NULL制約、また同じジャンルが複数登録されることを防ぐための一意性制約などをつけました。またER図のリレーションに沿って外部キー制約をつけます。UPDATE時の挙動やDELETE時の挙動を決める ON UPDATE ~, ON DELETE ~ は基本的に依存リレーションならば CASCADE, 非依存ならば RESTRICT を指定します。
これらのことを行なってできたのが以下です。
CREATE TABLE users (
user_id INTEGER PRIMARY KEY,
username VARCHAR(64) NOT NULL,
password VARCHAR(128) NOT NULL
);
CREATE TABLE authors (
author_id INTEGER PRIMARY KEY,
name VARCHAR(64) NOT NULL UNIQUE
);
CREATE TABLE genres (
genre_id INTEGER PRIMARY KEY,
name VARCHAR(128) NOT NULL UNIQUE
);
CREATE TABLE books (
book_id INTEGER PRIMARY KEY,
author_id INTEGER NOT NULL,
name VARCHAR(128) NOT NULL UNIQUE,
FOREIGN KEY (author_id) REFERENCES authors(author_id) ON DELETE CASCADE
);
CREATE TABLE books_genres (
book_id INTEGER NOT NULL,
genre_id INTEGER NOT NULL,
PRIMARY KEY(book_id,genre_id),
FOREIGN KEY (book_id) REFERENCES books(book_id) ON DELETE CASCADE,
FOREIGN KEY (genre_id) REFERENCES genres(genre_id) ON DELETE CASCADE
);
CREATE TABLE reads (
read_id INTEGER PRIMARY KEY,
user_id INTEGER NOT NULL,
book_id INTEGER NOT NULL,
thoughts VARCHAR(1024),
read_at DATE NOT NULL,
FOREIGN KEY (user_id) REFERENCES users(user_id) ON DELETE CASCADE,
FOREIGN KEY (book_id) REFERENCES books(book_id) ON DELETE CASCADE
);
CREATE TABLE follows (
follower_id INTEGER NOT NULL,
followee_id INTEGER NOT NULL,
PRIMARY KEY(follower_id,followee_id),
CHECK (followee_id <> follower_id),
FOREIGN KEY (follower_id) REFERENCES users(user_id) ON DELETE CASCADE,
FOREIGN KEY (followee_id) REFERENCES users(user_id) ON DELETE CASCADE
);
CREATE TABLE messages (
message_id INTEGER PRIMARY KEY,
sender_id INTEGER NOT NULL,
receiver_id INTEGER NOT NULL,
content VARCHAR(1024) NOT NULL,
send_at TIMESTAMP WITH TIME ZONE NOT NULL,
FOREIGN KEY (sender_id) REFERENCES users(user_id) ON DELETE CASCADE,
FOREIGN KEY (receiver_id) REFERENCES users(user_id) ON DELETE CASCADE
);
CREATE TABLE open_messages (
message_id INTEGER PRIMARY KEY,
sender_id INTEGER NOT NULL,
content VARCHAR(1024) NOT NULL,
send_at TIMESTAMP WITH TIME ZONE NOT NULL,
FOREIGN KEY (sender_id) REFERENCES users(user_id) ON DELETE CASCADE
);
-- view
CREATE VIEW book_author (
book_id,
book_name,
author_name
) AS
SELECT
b.book_id,
b.name AS book_name,
(SELECT a.name FROM authors AS a WHERE a.author_id = b.author_id) AS author_name
FROM books AS b;
最後のビューはよく使うと考えられるため追加しました。
インデックス設計
次にインデックス設計を行います。(ここではインデックスはB木インデックスということにします)。RDBMSにインデックスをつけるメリット、デメリットとしては
メリット
- WHERE句で特定のデータに絞るようなSELECTなどで高速化できることが期待できる。
デメリット
- インデックスは定義しても使われない場合があり、ディスクが無駄になる
- 更新、削除の際のコストは大きくなる。
があります。そのためインデックスをどこにつけるか/つけないか は効率化の上で考えるべきことですし、実際に効果があるかは実際のデータの分布などをみて決めないといけません。
ところで別の本(https://www.oreilly.co.jp/books/9784873119588/)にはインデックス作成の方針として
外部キー制約で参照されているすべての列にインデックスをつける。
といったことが書いてありました。なぜなら親行を消すときにかならず子行を参照するようになっているかららしいです。また外部キー制約がつくところで JOIN することが多いということもあるのではないかと思っています。
そこで実際に上のようにインデックスをつけることでクエリの実行時間に変化があるかをみてみたいと思います。上のテーブルとそれにインデックスとして
CREATE INDEX books_01 ON books (author_id);
CREATE INDEX books_genres_01 ON books_genres (book_id);
CREATE INDEX books_genres_02 ON books_genres (genre_id);
CREATE INDEX reads_01 ON reads (user_id);
CREATE INDEX reads_02 ON reads (book_id);
CREATE INDEX follows_01 ON follows (follower_id);
CREATE INDEX follows_02 ON follows (followee_id);
CREATE INDEX messages_01 ON messages (sender_id);
CREATE INDEX messages_02 ON messages (receiver_id);
CREATE INDEX open_messages_01 ON open_messages (sender_id);
を追加したものを比較してみます。テストデータとして約3万件の SELECT と INSERT 文を別に実行してみて time コマンドで実行時間(ディスクI/Oの待ちをみるため, real)を5回計測して平均を取ります。色々ファイル書き込みとかのオーバーヘッド込みですが簡易的なものということということで許してください。
実行環境は
- MacBook Air (Retina, 13-inch, 2018),1.6 GHz デュアルコアIntel Core i5
- PostgreSQL 13.3
です。詳細なコードはこちら
を参照してください。結果は以下のようになりました。
| 1回目/s | 2回目/s | 3回目/s | 4回目/s | 5回目/s | 平均/s | |
インデックスなし(INSERT) | 6.705 | 10.332 | 11.074 | 8.228 | 11.562 | 9.5802 |
インデックスなし(SELECT) | 4.225 | 4.570 | 4.259 | 4.579 | 7.063 | 4.8752 |
インデックスあり(INSERT) | 10.657 | 7.979 | 7.129 | 9.352 | 10.667 | 9.1568 |
インデックスあり(SELECT) | 3.879 | 2.862 | 2.933 | 3.087 | 2.983 | 3.1488 |
ばらつきはすこしあるようですが、SELECT ではインデックスありの方が平均的に早いように見えます。INSERT では差は小さいもののインデックス有りの方が少し早いです。検定などをして厳密に評価したわけではないですが、外部キーを参照している列にインデックスをつけることの効果はたしかに感じることができます。
おわりに
データベース設計はむずかしいし、奥が深い作業であるとわかりました。データモデリングチェックリストにはもっと多くの確認すべき項目があって、実用に耐えうるデータベースをつくるのはたいへんなのだろうと感じました。